DuckDB Bundle on Kubernetes
Exploring DuckDB using Apache Superset on K8s


What is DuckDB to me?
It’s an extremely fast Database, which outperforms many distributed databases. It’s designed for a single node and that makes it the perfect candidate for simplifying the data science workflow.
DuckDB interacts very well with Apache Arrow and Parquet.

Why Kubernetes?
Because that’s my infrastructure for the ML Platform.
A bit of Theory…
I am using Kubernetes Deployment for this example but will publish a helm chart as well.
Created a Docker File
Integrated Apache Superset 1.5.2 , DuckDB 0.5.1 & duckdb-engine 0.6.4
Created a default Superset admin user
Created a Default DuckDB Database in Superset named DuckDB 😁
Inside the database config, added connect_args for DuckDB to interact with AWS S3.
The Deployment file has nothing special and can be found in this github.
Deployment
Check out the deployment_duckdb_bundle.yaml
Make the following changes, *if required
tolerations, serviceAccountName, Affinity, resources
Post Launch Pre-configuration
After successful deployment, you need to port forward on 8088.
The first time after deployment, the user will have to do some pre configurations manual steps
Superset (1.5.2) has a bug where a database configuration doesn’t detect Allow DML option
It is mandatory to install `httpfs` on the superset. Even after Pip, duckdb didn’t recognize and needed an explicit installation
Finally, need to apply connect_arg on the Database, if the user needs to access AWS S3 bucket or MinIO
Walkthrough
Use the world’s most secure password admin/admin

Go to Data > Databases and edit the DuckDB database


Advanced > Allow DML and Save

Go to SQL Lab > SQL Editor and Run INSTALL ‘httpfs‘

Now you are ready, technically you can already run queries on local files or if you copy data in your pod.
For blob storage, do the following. Go to Data > Database > Edit > Advanced and add connect_args
{ "connect_args": { "preload_extensions": [ "httpfs" ], "config": { "s3_endpoint": "s3.XXX.amazonaws.com", "s3_region": "us-east-2", "s3_access_key_id": "XXXXXX", "s3_secret_access_key": "XXXXXXXYYYYYYY", "s3_url_style": "path", "s3_use_ssl": "false" } } }Explore Data
I am following this DuckDB Blog https://duckdb.org/2021/06/25/querying-parquet.html



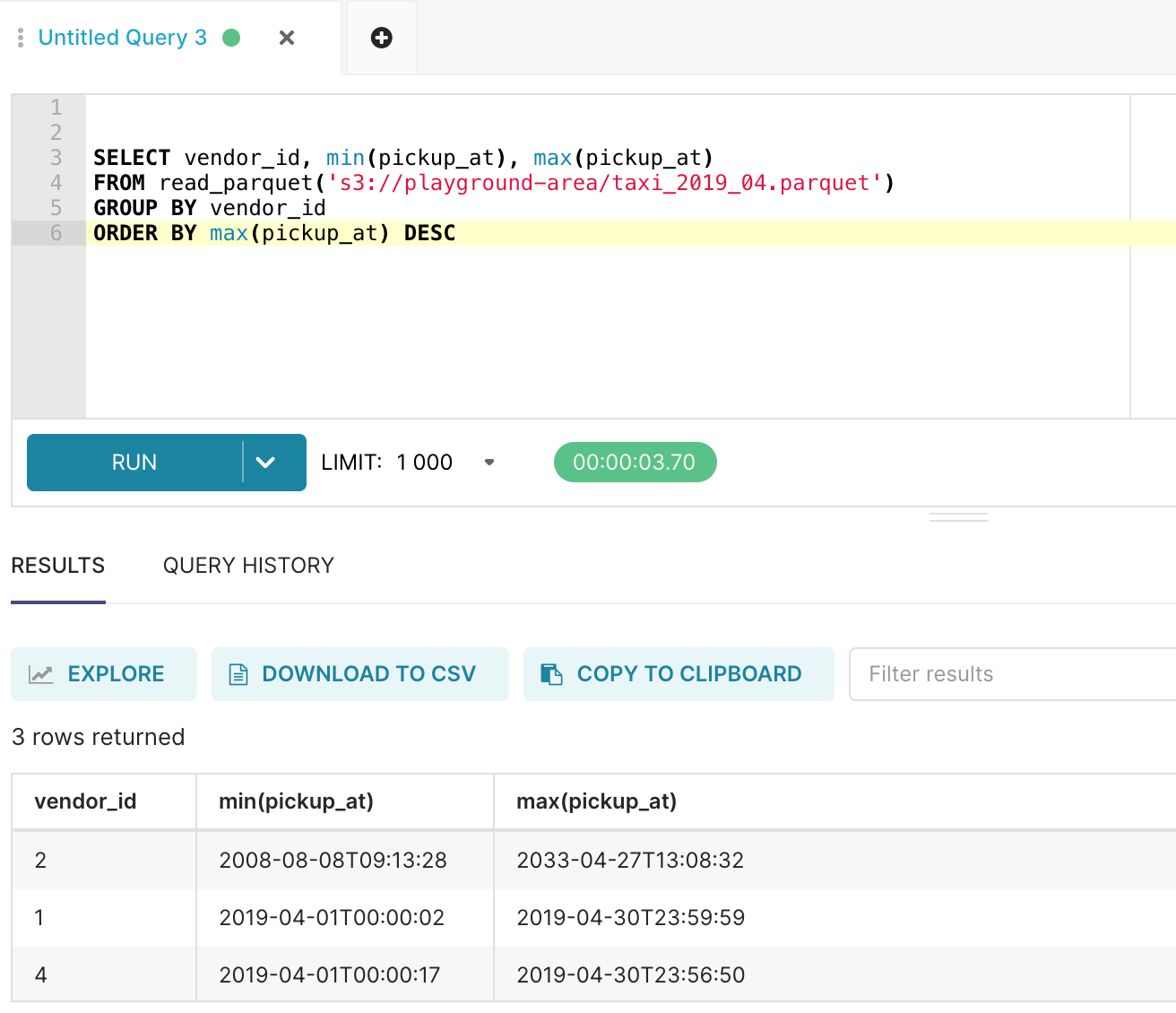
Observation
DuckDB performs surprisingly fast on Blob storage as well, unless there is an absolute millisecond response time required.
create Table AS on S3 parquet data is very slow
Processing a few million records with 20+ columns (S3 parquet) runs smoothly on DuckDB
My Memory Requirements
CPU : 2
RAM: 30GB